对话华为周斌:没有强大算力底座,大模型就没有根
时间:2023-05-27 10:41:12 来源:搜狐数码
 (资料图)
(资料图)
中新经纬5月27日电 (李自曼)“开发大模型的挑战,首当其冲是算力。算力是训练大模型的基础能力,开发建设大模型消耗的算力非常大。”26日,在中关村论坛平行论坛人工智能开放生态论坛上,华为昇腾计算业务CTO周斌在接受中新经纬等媒体采访时说。
华为昇腾计算业务CTO周斌 主办方供图
在支持大模型发展方面,华为想要达到怎样的自主水平?
在周斌看来,没有强大的算力底座,大模型就没有根。华为已为全国20多座城市提供了绿色稳定的算力基础设施,并提供从模型开发、微调适配、推理部署的全流程软件使能,来支持大模型的建设,促进中国人工智能生态发展。
周斌认为,当前中国在建设大模型方面有一定的优势。首先,中国有很多资源投入到大模型建设当中,各方资源正在有序协同发展,这使得中国可以在短时间内集合更大的力量攻克各种问题;其次,中国目前有很多可以对接大模型的应用场景,很多先行者和挑战者已经取得阶段性成果。
周斌指出,大模型的算力规模很快将从千亿规模升级到万亿级,这就需要公司在开发大模型过程中,提供安全、高效、可靠的AI的计算系统。其中,要着重把握数据安全,从技术手段和法律角度去保障数据隐私。
对于华为大模型的主要发展方向,周斌表示:“从昇腾计算业务部来看,我们会坚定地服务于整个国家的人工智能应用生态,提供人工智能的基础算力底座,打造更好用的人工智能训练系统、设备、计算系统。同时,会加强业务部署,跟国内的顶尖的科研机构联合创新,促进大模型生态的繁荣发展。”
据了解,“昇腾AI”基础软硬件平台已孵化和适配了30多个主流大模型,中国一半以上的原生大模型是基于“昇腾AI”。基于昇腾AI基础软硬件平台,华为联合各界伙伴一同打造了昇腾AI产业。截至目前,昇腾AI产业拥有20多家硬件伙伴,1100多家软件伙伴,并联合推出2000多个行业AI解决方案,开发者数量突破150万。
(更多报道线索,请联系本文作者李自曼:liziman@chinanews.com.cn
责任编辑:
标签:
最新文章推荐
- 百科 日本无条件投降书详细内容是什么
- 知识 大连铁道学院是几本有三本吗
- 知识 什么是OLED
- 知识 重阳节用英语怎么说
- 知识 螺旋测微器的读数方法
- 知识 京AG6是什么意思
- 知识 中华鲟鱼又叫什么
- 知识 杜鹃鸟为什么不停的叫
- 知识 办理兵役证需要带什么证件
- 陕西7名核酸检测阳性外省游客活动轨迹公布
X 关闭
资讯中心
 厦门保障性租赁房认定细则发布 配租面向新市民群体年度租金涨幅不超过5%
厦门保障性租赁房认定细则发布 配租面向新市民群体年度租金涨幅不超过5%
2022-05-20
2021-10-18
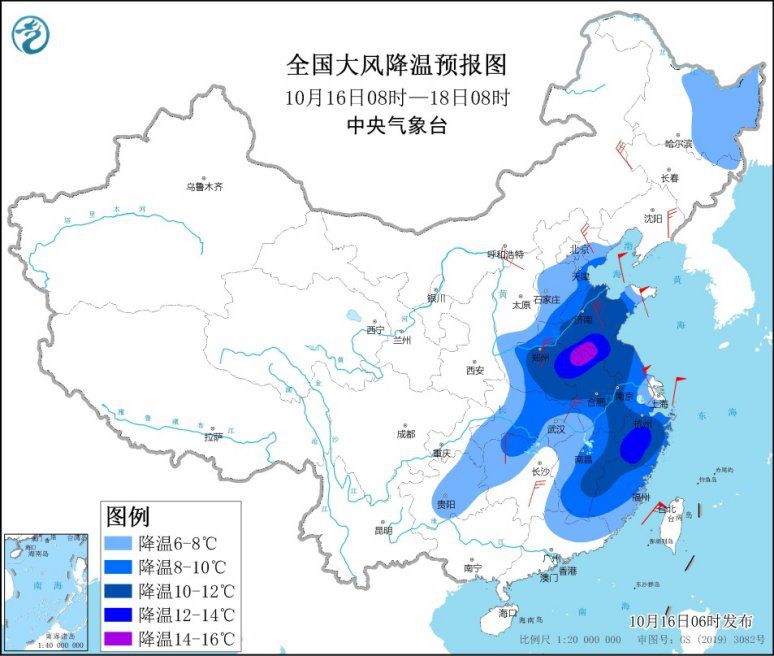 强冷空气继续影响中东部地区 局地降温14℃以上
强冷空气继续影响中东部地区 局地降温14℃以上
2021-10-18
 中东部多地将迎立秋后最冷周末 雨雪天气持续
中东部多地将迎立秋后最冷周末 雨雪天气持续
2021-10-18
X 关闭
热点资讯
-
1
对话华为周斌:没有强大算力底座,大模型就没有根
-
2
我就是喜欢我绘本故事读后感_我就是喜欢我的故事
-
3
男子深夜停车场里“拉呀拉呀拉” “盲盒”没开成民警却到了|天天热闻
-
4
中直党建杂志社级别_中直党建网
-
5
天天快资讯:事关住房公积金,最新通知
-
6
天天观点:婚礼婆婆礼服蕾丝长裙_婚礼婆婆礼服
-
7
网络电视看电视台节目_网络电视如何收看电视节目
-
8
每日观察!体检季到了,你的报告是否出现“肺结节”?专家支招不必慌
-
9
环球速讯:上交所调整上证50、上证180、上证380、科创50等指数样本
-
10
农业合作社提取盈余公积账务处理_提取盈余公积账务处理 快播报
-
11
小米 Civi 3 上手评测:质的飞越,美的终极展现
-
12
老龄化程度加深 科研人员耗时20余载研制新材料助力“骨修复”
-
13
湘西保靖县普戎镇:文明条例入人心,文明行为我先行
-
14
“怀柔通”预约挂号即将停用,新的挂号方式看这里
-
15
记者:曼联队被告知,如果他在同意金玟哉的交易后想...
-
16
今日要闻!李彦宏称未来薪酬水平将取决于提示词写得好不好
-
17
方邦股份: 2022年股票期权激励计划预留授予激励对象名单
-
18
【环球时快讯】大学英语四级考试(大学英语 四)
-
19
天天看点:兴业银行兰州分行举办“小小银行家”金融知识普及系列活动
-
20
请成为我的家人更新时间